
Forgetting is Not Always Bad
I was recently reminded of a scene in the sci-fi novel “Sleeping Giants”, where the main character is presented with a fascinating thought experiment about squirrels and how they store food for seasons of scarcity. To paraphrase briefly:
A squirrel gathers far more seeds and nuts than it could possibly consume, hiding this bounty by burying them in seemingly random places. It might stash a thousand nuts or more in a single fall. In spring, it digs, appearing to search at random, in an effort to find enough food to eat.
If a squirrel had perfect memory, we might assume it could gather its food more easily and efficiently. It would remember every single location where it dug and could go directly to each spot to retrieve its treasure. But what would the true outcome be?
The squirrel would starve.
Other animals would have already pillaged some, if not all, of the squirrel’s reserves. Instead of taking cues from its environment, it relies on its perfect memory. In doing so, it often turns up empty-handed more than it gains food. In this case, its limited memory is a true evolutionary advantage.
What Should We Forget?
It’s not that we should simply forget everything. It’s that the things we need to remember may not be in the minute details of what we experience. For the squirrels, maybe it’s more important to recall general areas where nuts are buried, or what the ground looks like when food is stored below. (It’s important to note, that I have no idea if the squirrel-story is accurate, because it came from a fictional book about giant robots, but it’s a great place to help us start thinking.)
Tell yourself a short story about a recent event in your life that involves another person (we’ll call this person “Mark”). Find two other people who do not know Mark, and share the same story with them. After a few days, ask them to recount the story back to you. What details did they remember? What did they leave out?
If I were one of those people, I likely would have forgotten Mark’s name, but I would remember general concepts about where the event took place and what that event was. I might vaguely recall that it happened recently, but I would not remember the exact date and time. However, if you asked me, “Remember that story I told you about my friend, Mark?” I could probably start to recall the event.
Recall
Imagine my brain as a contextual database of fragmented memories. If you asked me, “Do you know my friend, Mark?” how would I search for that information?
I could look for the name “Mark,” but I would be overwhelmed with other unrelated Marks. I might search for “friends of yours,” which could yield a list of individuals mentioned more frequently than Mark. If I searched for “recently mentioned friends,” the list would shorten, and I might deduce that one of the nameless friends must be Mark. I would likely want to confirm that assumption with you. That is how I envision my digital memories functioning.
Dual Storage
Take a look at the following table. This is a typical starting point for allowing AI models to work with historical context.
| ID | full_memory_text |
|---|---|
| 1 | Last week, Mark and I… |
| 2 | Yesterday, I went to the store and… |
We already have tools to semantically search the full text results (though we may need to break the text into chunks depending on our tooling). This means we can search for terms like “Mark,” “In the past,” or “grocery visit,” and still find the most relevant text for those kinds of queries.
But is there a better way? Absolutely. If we can divide and transform our text into more meaningful pieces based on the types of questions we anticipate, we can enhance both how we store and how we query our memories.
As an important note, this concept is neither new nor original; it is currently being studied, tested, and even packaged into reusable software. If you are interested in reading (or listening to the live poster presentation), there is an excellent article on this subject where the researchers refer to this kind of process as “Graph Neural Prompting”.
Let’s create more human-like memories, where we chunk the experiences (our journal entries) into some sparse but meaningful concepts.
Imagine I took our story with Mark and asked a Large Language Model to generate several summaries around the following themes:
- Who was involved and the subject’s relationship with them?
- What happened during the event?
- What are some general concepts around the event?
Each summary would likely be shorter than the original story (and we can influence this with some straightforward prompting), making them easier to target in specific ways. The hypothesis is that by cutting down the information and focusing it, we are going to reduce hallucinations and improve relevancy in our responses. (I think of this as a cheating form of intentional forgetting!)
Of course, we would still retain the full text, allowing us to search against that as needed. The real magic here is that we can start building a system to query this data for a rich AI conversation.
A Robot Conversation Partner
Last week, OpenAI rolled out the capability to optionally reference past conversations (a very useful “memory” feature). This feature has proven very helpful when answering questions as an assistant.
However, it hasn’t yet achieved that human feel I crave. I wanted to see if I could get closer to “humanity” in my own way. Based on my research into Graph Neural Prompting and my distant undergrad studies in psychology, I created a project with roughly the following flow:
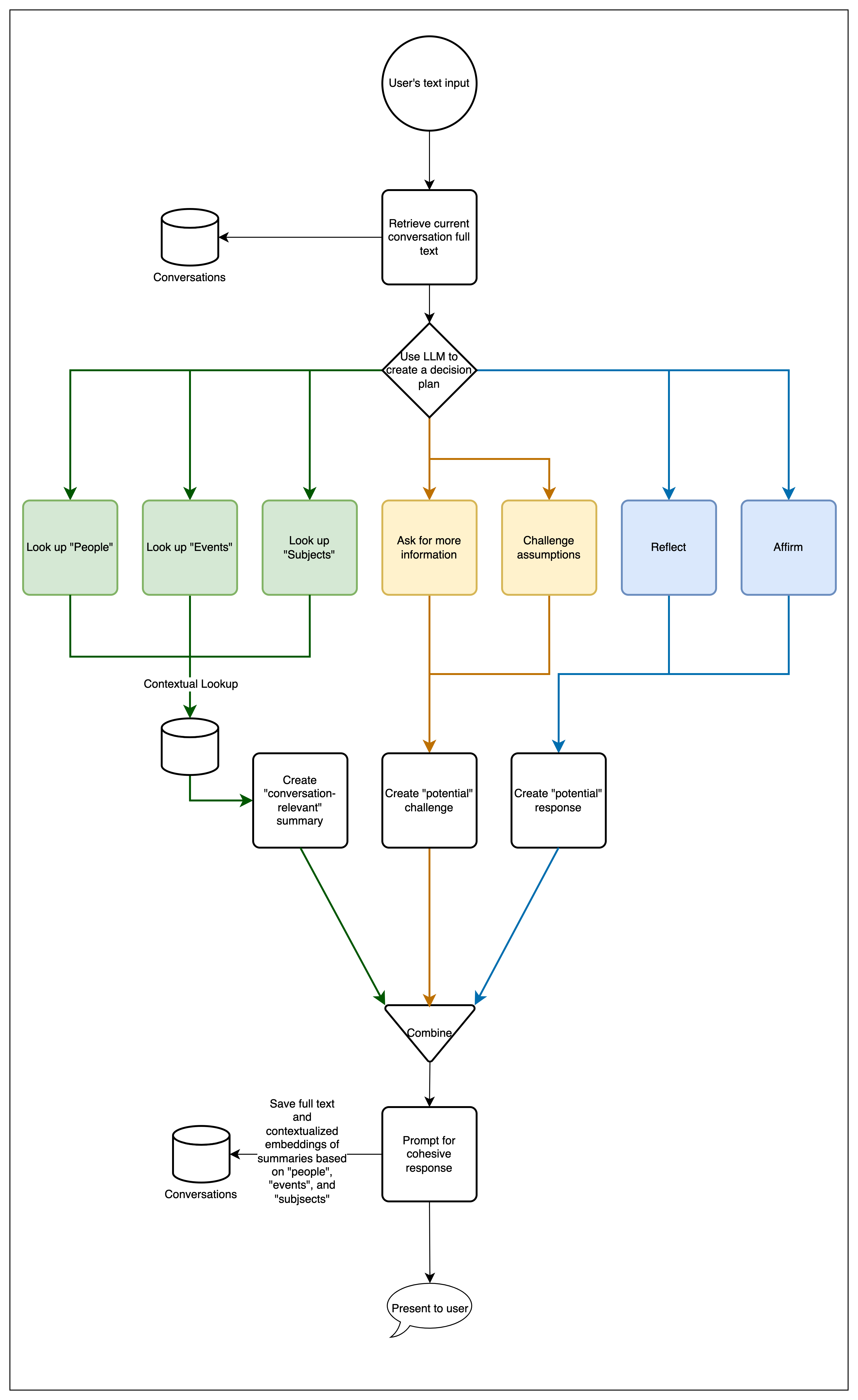
What’s happening here?
- Whenever we get a new entry from the user, we use an LLM to make a “decision plan”, which is a list of steps to execute in order to provide the most helpful response.
-
Plan options:
- Look up people
- Look up events
- Look up subjects
- Ask the user for more information
- Challenge some part of the user’s entry
- Reflect/mirror/rephrase the user’s entry back to them
- Affirm/promote the user’s entry
-
Plan options:
- For each lookup step, we prompt the LLM to create a statement (or series of statements) to assist us in a semantic search against each concept.
- We use the LLM to create a contextually relevant context based on the data returned from our searches.
- We continually add and stack up the contexts of each lookup step to further inform sequential steps.
- We create individual responses for each of the response/challenge decisions.
- We combine all of the generated contexts and responses, and we feed them back to the LLM with a prompt to aggregate, condense, and prune until we have a single, cohesive response for the user.
- We use an LLM to create concept-specific statements for the user’s entry.
- We create and store embeddings of the user’s concept-specific statements, along with an embedding of the full text, and the full text itself.
The results are promising! After a few conversations, you might find a dialogue that unfolds roughly like this (simulated, since my personal journal is… personal):
AI: What’s on your mind?
Me: Just thinking about my blog post on human-AI interactions…
AI: You talk about that a lot. 🙂 You seem to have developed a passion for working with AI. What’s your post focused on?
Me: It’s about making an AI agent’s memory work more like human memory and striving for more natural conversations.
AI: That sounds like its related to the AI journal project you told me about. Are you looking deeper into some of those theories you mentioned last week? Or do you have a new approach?
Where to go from here?
The power of a system like this is that we can actually do a bit of time traveling and create new, better conceptual embeddings based on older conversations. We can even get into some meta-situations, where we constantly evaluate our past conversations and “reorganize” our memories into new, dynamic concepts.
I’m interested in refining some of this work and in experimenting further with theories that provide models around brain plasticity, short-term vs long-term memory, and also adding time-weighted/temporary attitude to responses based on previous conversations.
TL;DR:
Forgetting (but remembering the important bits) is really important, not so much to save on space (though space is an important factor), but to help us recall things in a natural, useful way.
We can implement a type of forgetting by creating concept-based embeddings that reduce the information stored. Ideally this leads to less hallucinations/irrelevant lookups and more meaningful data retrieval.
We can iterate on these approaches and make our human-machine interactions less mechanical and even evolutionary.
We know we can do these things, but should we?
It’s a question for another day!
Leave a Reply